2D Parallelism using PyTorch in Ray
Last time we already covered Tensor Parallelism using PyTorch Distributed Elastic and little bit of Pipeline Parallelism, but did you know that you can combine Tensor Parallelism and Pipeline Parallelism in the same parallelism? Actually we got up to 4D! Tensor Parallelism + Pipeline Parallelism + Data Parallelism + Context Parallelism, TP + PP + DP + CP! But this blog we will only cover TP and PP.
As we know, Tensor Parallelism split the weights either Row-Wise or Column-Wise to N GPUs and Pipeline Parallelism split hidden layers to N GPUs,
We can combine TP and PP to become a single parallelism, called 2D Parallelism. Assumed I have a deep learning model with 4 hidden layers, and each hidden layer got a linear layer, to make the model fit into 2D Parallelism,
- GPU 0 take hidden layers 0-1, this is a PP for hidden layers 0-1, and GPU 0 TP with GPU 1 to shard the weights, this can be done using `torch.distributed.new_group`. This required 2 GPUs.
- Output from hidden layers 0-1 in GPU 0 and will pass to GPU 2, and GPU 2 PP hidden layers 2-3. GPU 2 TP with GPU 3 to shard the weights. Also required to create new group using `torch.distributed.new_group`. This required 2 GPUs.
- The number of GPUs required is, M PP x N TP, if M = 2 and N = 2, we need 4 GPUs. 1 PP 2 TP means, all hidden layers inside the same GPU 0, but the weights sharded with GPU 1, so it required 2 GPUs.
- Because the hidden layers are split across M devices, and each weight is sharded by N, GPU memory is saved by a factor of M x N!
- This 2D Parallelism communication groups are like below,
- TP Group: [0, 1] is the TP communication group for GPU 0 and GPU 1, PP Group: [0, 2] is the PP communication group for GPU 0 and GPU 2, and TP Group: [2, 3] is the TP communication group for GPU 2 and GPU 3.
PyTorch in Ray
For distributed framework we decided to use Ray (Please sponsor us something) because we do not have a node with 4 GPUs, but we got 2 nodes with each 2 GPUs, so we connect those nodes using Ray inside Tailscale VPN.
Why Ray? Ray is cool, nice UI, and the important parts are, node auto discovery and automatic distributed execution.
What does means by node auto discovery and automatic distributed execution? actually Torch Elastic Distributed support multi-nodes natively, you must set rendezvous backend, https://pytorch.org/docs/stable/elastic/run.html#note-on-rendezvous-backend
```bash torchrun --nnodes=$NUM_NODES --nproc-per-node=$NUM_TRAINERS --rdzv-id=$JOB_ID --rdzv-backend=c10d --rdzv-endpoint=$HOST_NODE_ADDR YOUR_TRAINING_SCRIPT.py ```
- `$NUM_NODES` must set equal to the size of nodes.
- `$NUM_TRAINERS` must set equal to the size of GPUs.
- `$JOB_ID` can set any ID, if you have multiple jobs, you must set different ID.
- `$HOST_NODE_ADDR` is the first node or the fastest node you have, and it will elect as host.
Now we have 2 nodes and each node got 2 GPUs, with IPs `100.93.25.29` and `100.92.17.27`, so to run using torchrun,
In `100.93.25.29`,
```bash torchrun \ --nnodes=2 --nproc_per_node=2 \ --rdzv_id=1234 --rdzv_backend=c10d --rdzv_endpoint=100.93.25.29:29500 train.py ```
And in `100.92.17.27`, you have to run the same thing,
```bash torchrun \ --nnodes=2 --nproc_per_node=2 \ --rdzv_id=1234 --rdzv_backend=c10d --rdzv_endpoint=100.93.25.29:29500 train.py ```
Which is tedious, and each nodes must have the same script plus you must know the head of IP address! Or maybe you saw someone run using Slurm before,
```bash
nodes=( $( scontrol show hostnames $SLURM_JOB_NODELIST ) )
nodes_array=($nodes)
head_node=${nodes_array[0]}
head_node_ip=$(srun --nodes=1 --ntasks=1 -w "$head_node" hostname --ip-address)
srun torchrun \
--nnodes 2 \
--nproc_per_node 2 \
--rdzv_id 1234 \
--rdzv_backend c10d \
--rdzv_endpoint $head_node_ip:29500 \
train.py
```
Slurm also run the script for the entire nodes register in Slurm, but in other to build a Slurm cluster,
```bash # /etc/slurm-llnl/slurm.conf ClusterName=my_cluster ControlMachine=100.93.25.29 # extra configs NodeName=node1 NodeAddr=100.93.25.29 RealMemory=32000 Sockets=1 CoresPerSocket=4 ThreadsPerCore=2 Gres=gpu:2 NodeName=node2 NodeAddr=100.92.17.27 RealMemory=32000 Sockets=1 CoresPerSocket=4 ThreadsPerCore=2 Gres=gpu:2 PartitionName=debug Nodes=node1,node2 Default=YES MaxTime=INFINITE State=UP ```
You need to put the config for the all nodes available, and as you can see, you have to mention all the IP nodes!
But in Ray, you do not have to do all of that, you just run the script anywhere as long the script connected to the Ray head and Ray will automatically distribute the script to another nodes.
In head node 100.93.25.29, you have to run the Ray head mode,
```bash ray start --head --node-ip-address=100.93.25.29 --port=6379 --dashboard-host=0.0.0.0 ```
After that other nodes just connect using,
```bash ray start --address=100.93.25.29:6379 ```
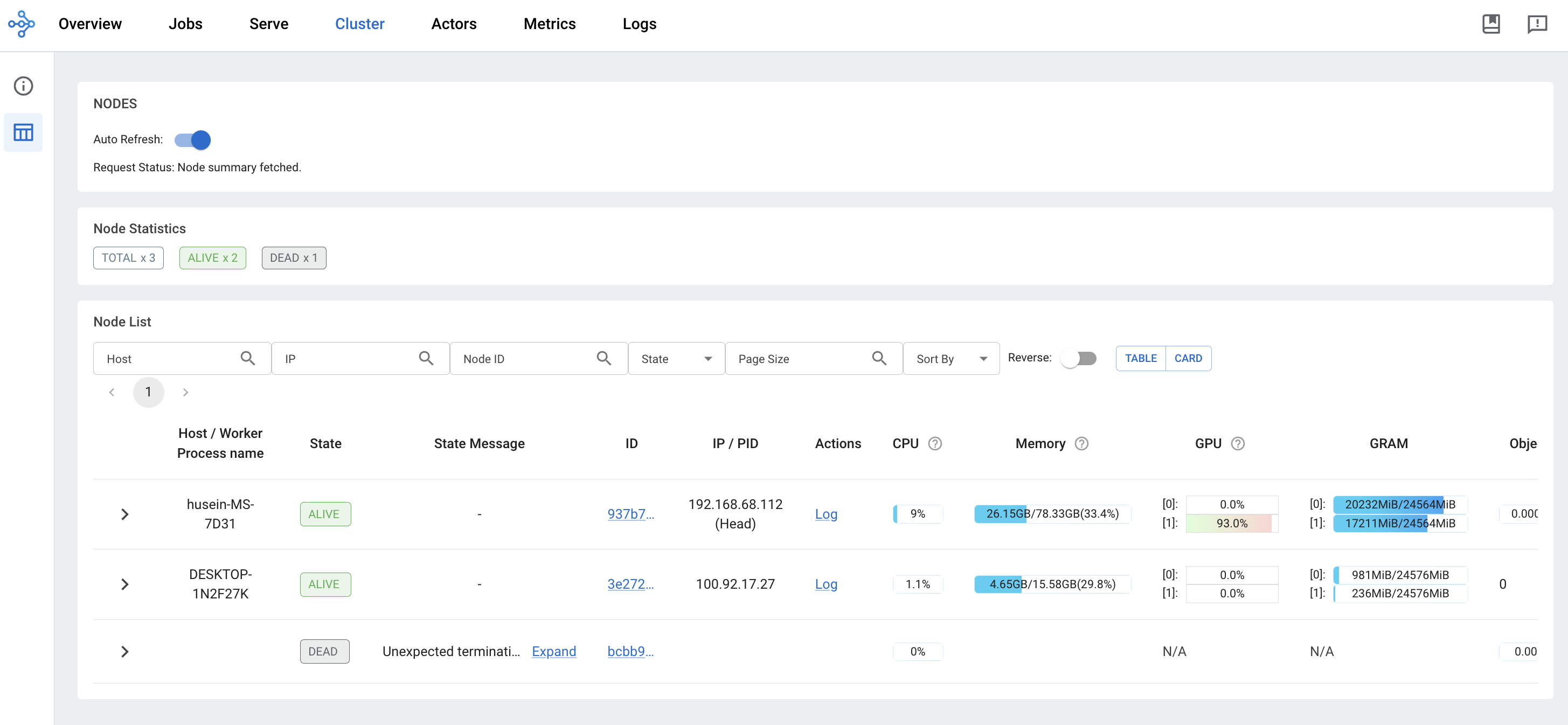
Done! The cluster looks like below,
Even though to connect to the Ray must use the head node, but all the nodes in the Ray cluster able to peer-to-peer communication without need to go the head node. And Ray comes with a nice dashboard!
Also natively with Prometheus metrics (but we are not deployed it, too lazy), you can read more at https://www.anyscale.com/blog/monitoring-and-debugging-ray-workloads-ray-metrics, so when talk about Prometheus, you can setup real-time alerts to any channels that you want, for an example, GPU temp reached >80c so you can send alert to Slack.
Let us look into Ray,
```python
import torch
import torch.nn as nn
import torch.distributed as dist
import os
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
def func():
print(os.environ['LOCAL_RANK'], os.environ['RANK'], os.environ["WORLD_SIZE"], os.environ["NODE_RANK"])
def main():
ray.init(address="ray://localhost:10001")
scaling_config = ScalingConfig(
num_workers=4,
use_gpu=True,
)
ray_trainer = TorchTrainer(
func,
scaling_config=scaling_config,
)
ray_trainer.fit()
if __name__ == "__main__":
main()
```
And save it as `test-ray.py`. If you have 4 GPUs, set `num_workers=4`, one worker equal to one GPU if `use_gpu=True`. In order to use PyTorch Distributed in Ray, you must use `TorchTrainer`. If you look at the source code of `TorchTrainer`, https://github.com/ray-project/ray/blob/master/python/ray/train/torch/config.py#L153, behind the scene it still use native `torch.distributed.run` and properly setup the `MASTER_ADDR`, https://github.com/ray-project/ray/blob/master/python/ray/train/torch/config.py#L169
```python
def set_env_vars(addr, port):
os.environ["MASTER_ADDR"] = addr
os.environ["MASTER_PORT"] = str(port)
worker_group.execute(set_env_vars, addr=master_addr, port=master_port)
```
If you read the documentation at https://pytorch.org/docs/stable/elastic/run.html#module-torch.distributed.run in the Note side, torchrun is a python console script to the main module torch.distributed.run declared in the entry_points configuration in setup.py. It is equivalent to invoking python -m torch.distributed.run. So basically `TorchTrainer` is also like `torchrun`, it just help you to set the arguments automatically.
Now let us run `test-ray.py`,
```bash python3 test-ray.py ``` ```text (TunerInternal pid=14055) Training started without custom configuration. (RayTrainWorker pid=2180081, ip=100.92.17.27) Setting up process group for: env:// [rank=0, world_size=4] (TorchTrainer pid=2179995, ip=100.92.17.27) Started distributed worker processes: (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.92.17.27, pid=2180081) world_rank=0, local_rank=0, node_rank=0 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.92.17.27, pid=2180082) world_rank=1, local_rank=1, node_rank=0 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.93.25.29, pid=14206) world_rank=2, local_rank=0, node_rank=1 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.93.25.29, pid=14207) world_rank=3, local_rank=1, node_rank=1 (RayTrainWorker pid=14207) 1 3 4 1 (RayTrainWorker pid=14206) 0 2 4 1 (RayTrainWorker pid=2180081, ip=100.92.17.27) 0 0 4 0 (RayTrainWorker pid=2180082, ip=100.92.17.27) 1 1 4 0 ```
The important logs,
```text (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.92.17.27, pid=2180081) world_rank=0, local_rank=0, node_rank=0 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.92.17.27, pid=2180082) world_rank=1, local_rank=1, node_rank=0 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.93.25.29, pid=14206) world_rank=2, local_rank=0, node_rank=1 (TorchTrainer pid=2179995, ip=100.92.17.27) - (ip=100.93.25.29, pid=14207) world_rank=3, local_rank=1, node_rank=1 ```
Here you can clearly see local ranks, node ranks and world ranks.
Actual 2D Parallelism
Now the actual 2D Parallelism, it is quite simple actually,
```python
import torch
import torch.nn as nn
import torch.distributed as dist
import os
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
class Linear(nn.Module):
def __init__(self, in_features, out_features, group, ranks):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.rank = int(os.environ['RANK'])
self.local_rank = int(os.environ['LOCAL_RANK'])
self.group = group
self.ranks = ranks
self.group_rank = dist.get_group_rank(self.group, self.rank)
self.world_size = group.size()
self.device = f'cuda:{self.local_rank}'
self.local_in_features = in_features
self.local_out_features = out_features // self.world_size
self.linear = nn.Linear(self.local_in_features, self.local_out_features)
def forward(self, x, batch_size, broadcast = True):
if broadcast:
if self.group_rank == 0:
dist.broadcast(x, src=self.ranks[0], group=self.group)
else:
x = torch.zeros(batch_size, self.local_in_features, device=self.device)
dist.broadcast(x, src=self.ranks[0], group=self.group)
local_output = self.linear(x)
gathered_out = [torch.zeros_like(local_output) for _ in range(self.world_size)]
dist.all_gather(gathered_out, local_output, group = self.group)
gathered_out = torch.cat(gathered_out, dim=-1)
print(self.rank, gathered_out.shape)
return gathered_out
def func():
rank = int(os.environ['RANK'])
tp_group1 = dist.new_group([0, 1])
tp_group2 = dist.new_group([2, 3])
pp_group = dist.new_group([0, 2])
batch_size = 32
input_shape = 50
output_shape = 4
if rank in [0, 1]:
linear1 = Linear(input_shape, input_shape, tp_group1, [0, 1])
linear1 = linear1.to(linear1.device)
linear2 = Linear(input_shape, input_shape, tp_group1, [0, 1])
linear2 = linear2.to(linear2.device)
linear3 = None
linear4 = None
else:
linear1 = None
linear2 = None
linear3 = Linear(input_shape, input_shape, tp_group2, [2, 3])
linear3 = linear3.to(linear3.device)
linear4 = Linear(input_shape, output_shape, tp_group2, [2, 3])
linear4 = linear4.to(linear4.device)
if rank in [0, 1]:
if rank == 0:
input_tensor = torch.randn(batch_size, input_shape, device=linear1.device)
else:
input_tensor = None
out1 = linear1(input_tensor, batch_size, broadcast = True)
out2 = linear2(out1, batch_size, broadcast = False)
if rank == 0:
dist.broadcast(out2, src=0, group = pp_group)
else:
if rank == 2:
out2 = torch.zeros(batch_size, input_shape, device=linear3.device)
dist.broadcast(out2, src=0, group = pp_group)
else:
out2 = None
out3 = linear3(out2, batch_size, broadcast = True)
out4 = linear4(out3, batch_size, broadcast = False)
print(out4.shape)
def main():
runtime_env = {
'env_vars': {
'NCCL_SOCKET_IFNAME': 'tailscale0',
}
}
ray.init(address="ray://localhost:10001", runtime_env = runtime_env)
scaling_config = ScalingConfig(
num_workers=4,
use_gpu=True,
)
ray_trainer = TorchTrainer(
func,
scaling_config=scaling_config,
)
ray_trainer.fit()
if __name__ == "__main__":
main()
```
Save it as `2d-parallelism.py` and run it,
```bash python3 2d-parallelism.py ```
The output,
```bash (RayTrainWorker pid=2423679) 1 torch.Size([32, 50]) (RayTrainWorker pid=2423679) 1 torch.Size([32, 50]) (RayTrainWorker pid=2423678) 0 torch.Size([32, 50]) (RayTrainWorker pid=2423678) 0 torch.Size([32, 50]) (RayTrainWorker pid=2284881, ip=100.92.17.27) 3 torch.Size([32, 50]) (RayTrainWorker pid=2284881, ip=100.92.17.27) 3 torch.Size([32, 4]) (RayTrainWorker pid=2284881, ip=100.92.17.27) torch.Size([32, 4]) (RayTrainWorker pid=2284880, ip=100.92.17.27) 2 torch.Size([32, 50]) (RayTrainWorker pid=2284880, ip=100.92.17.27) 2 torch.Size([32, 4]) (RayTrainWorker pid=2284880, ip=100.92.17.27) torch.Size([32, 4]) ```
You can see `3 torch.Size([32, 4])`, which is the last output that we want. So the flow is like,
- 1. You need to make sure you set `'NCCL_SOCKET_IFNAME': 'tailscale0'`. Because we use Tailscale, we set it `tailscale0`, verify using `ifconfig`. This is to let NCCL know which network need to use for the communication. You can put multiple networks split by commas.
- 2. Initialize communication group,
-- i. `tp_group1 = dist.new_group([0, 1])` between GPU 0 and GPU 1.
-- ii. `tp_group2 = dist.new_group([2, 3])` between GPU 2 and GPU 3.
-- iii. `pp_group = dist.new_group([0, 2])` between GPU 0 and GPU 2.
- 3. Initialize all the layers using If-Else statement, you can do it better to support dynamic layers.
-- i. `if rank in [0, 1]: linear1 = Linear(input_shape, input_shape, tp_group1, [0, 1])`. GPU 0 and GPU 1 both initialized `linear1` with the communication `tp_group1`.
-- ii. `if rank in [0, 1]: linear2 = Linear(input_shape, input_shape, tp_group1, [0, 1])`. GPU 0 and GPU 1 both initialized `linear2` with the communication `tp_group1`.
-- iii. `if rank in [2, 3]: linear3 = Linear(input_shape, input_shape, tp_group2, [2, 3])`. GPU 2 and GPU 3 both initialized `linear3` with the communication `tp_group2`.
-- iv. `if rank in [0, 1]: linear4 = Linear(input_shape, input_shape, tp_group2, [2, 3])`. GPU 3 and GPU 3 both initialized `linear4` with the communication `tp_group2`.
- 4. `def __init__(self, in_features, out_features, group, ranks)` The reason why we pass the `ranks` is to make sure during the broadcast, the broadcaster come from the local group `src`, `dist.broadcast(x, src=self.ranks[0], group=self.group)`.
- 5. `self.group_rank = dist.get_group_rank(self.group, self.rank)` this also to get the ranks based on the group, if the group is [2, 3], so the group rank is [0, 1]. When group is rank == 0, we can do broadcast if you want.
- 6. `self.device = f'cuda:{self.local_rank}'`. The reason why `self.device` must use local rank because, as we know, we got 2 nodes, each node with 2 GPUs, even though the second GPU and the second node is rank 3, but local rank is 1. So you must initialize as `cuda:1` at the second node.
- 7. We initialized 4 hidden layers, each hidden layer got a linear layer with size 50x50, except for the last layer is 50x4. Because each hidden layer been TP,
-- first layer, GPU 0 50x25 GPU 1 50x25.
-- second layer, GPU 0 50x25 GPU 1 50x25.
-- third layer, GPU 2 50x25 GPU 3 50x25.
-- fourth layer, GPU 2 50x2 GPU 3 50x2.
- The data flow,
- 8. the input with size 32x50 will initialize at GPU 0, this will broadcast using `dist.broadcast` to GPU 1 using TP Group: [0, 1].
- 9. On the first hidden layer, now GPU 0 input 32x50 matmul 50x25 = 32x25, GPU 1 input 32x50 matmul 50x25 = 32x25, and do `dist.all_gather`. So GPU 0 and GPU 1 will got the same list of matrices [32x25, 32x25], and GPU 0 and GPU 1 will do concatenation on the last dimension, so it will become 32x50, ready to pass to second hidden layer.
- 10. On the second hidden layer, now GPU 0 input 32x50 matmul 50x25 = 32x25, GPU 1 input 32x50 matmul 50x25 = 32x25, and do `dist.all_gather`. So GPU 0 and GPU 1 will got the same list of matrices [32x25, 32x25], and GPU 0 and GPU 1 will do concatenation on the last dimension, so it will become 32x50, ready to broadcast to GPU 2 using PP Group: [0, 2].
- 11. GPU 0 will broadcast using `dist.broadcast` to GPU 2 using PP Group: [0, 2], so GPU 2 input is 32x50.
- 12. GPU 2 will broadcast using `dist.broadcast` to GPU 3 using TP Group: [2, 3], so GPU 3 input is 32x50.
- 13. On the third hidden layer, now GPU 2 input 32x50 matmul 50x25 = 32x25, GPU 3 input 32x50 matmul 50x25 = 32x25, and do `dist.all_gather`. So GPU 2 and GPU 3 will got the same list of matrices [32x25, 32x25], and GPU 0 and GPU 1 will do concatenation on the last dimension, so it will become 32x50, ready to pass to fourth hidden layer.
- 14. On the fourth hidden layer, now GPU 2 input 32x50 matmul 50x2 = 32x2, GPU 3 input 32x50 matmul 50x2 = 32x2, and do `dist.all_gather`. So GPU 2 and GPU 3 will got the same list of matrices [32x2, 32x2], and GPU 2 and GPU 3 will do concatenation on the last dimension, so it will become 32x4, ready to pass back to CPU.
- 15. The data movement is like below,
Super cool right?